MarketLens
Ask a chatbot about the market and it answers from parametric memory: unsourced, unreproducible, stale. MarketLens takes the opposite bet. Ingest the primary sources, embed and cluster everything, and compute research from the corpus. The local LLM gets three narrow jobs and no opinions.
The pipeline
Five stages, every one auditable back to rows in Postgres.
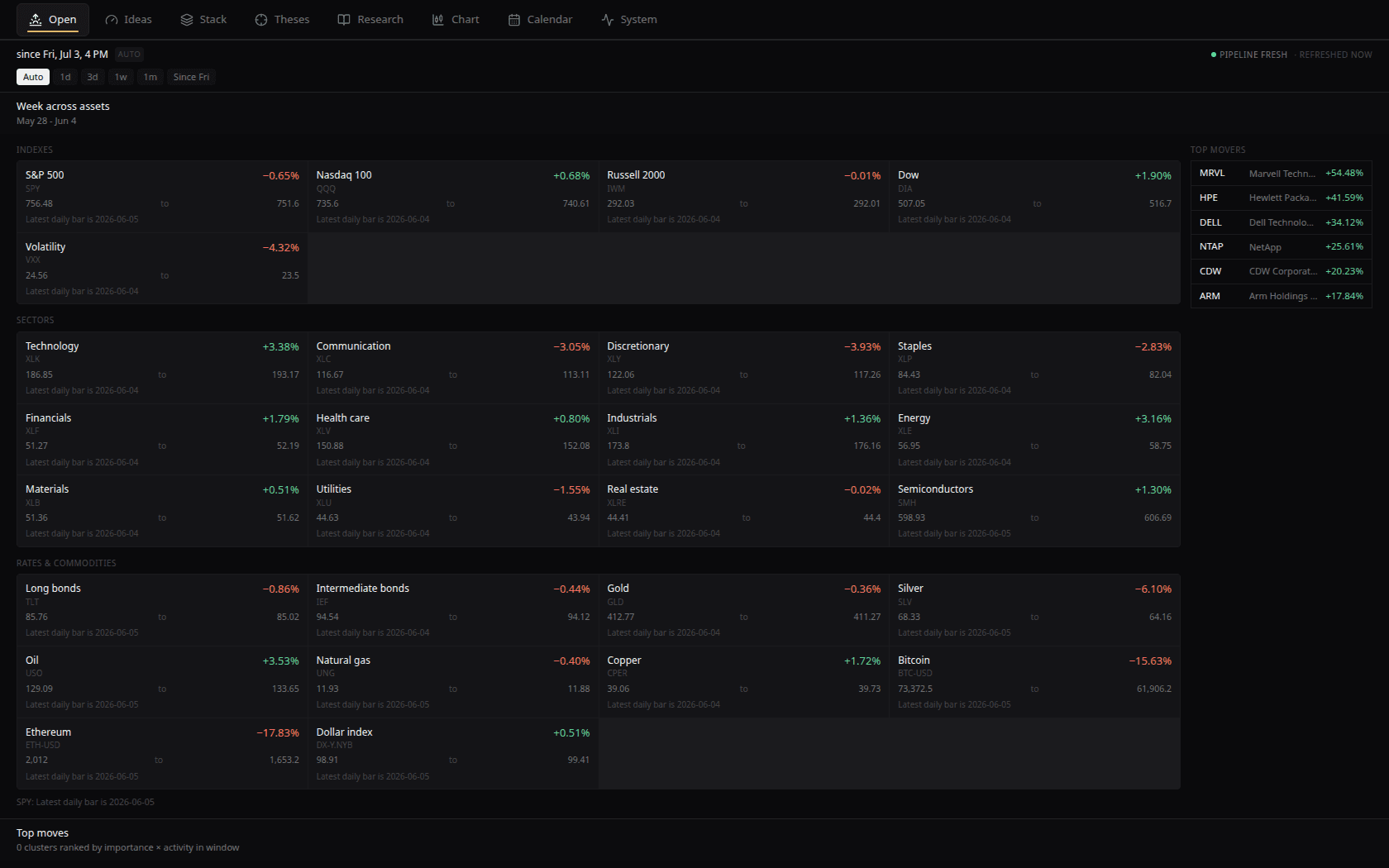
- Ingestion: SEC EDGAR per-CIK, wire RSS, company IR feeds, FRED/BLS/BEA macro series, Fed communications, FTC/DOJ/SEC enforcement, the Federal Register, CourtListener litigation, Reddit, Finnhub. Earnings calls transcribed on-host by Whisper.
- Embedding: every article gets a 1024-dim embedding, then pgvector nearest-neighbor assignment into deduplicating clusters, 7-day window, 0.85 cosine.
- Triage: a zero-shot classifier gates each cluster against a typed event vocabulary. Below threshold, the cluster never reaches the LLM.
- Extraction: the local model sees a cluster, never a single headline. Constrained JSON out: slots, sentiment, magnitude. The event type is given, not asked.
- Importance: source weight × novelty × event-class prior × magnitude. Arithmetic. The model never produces the score.
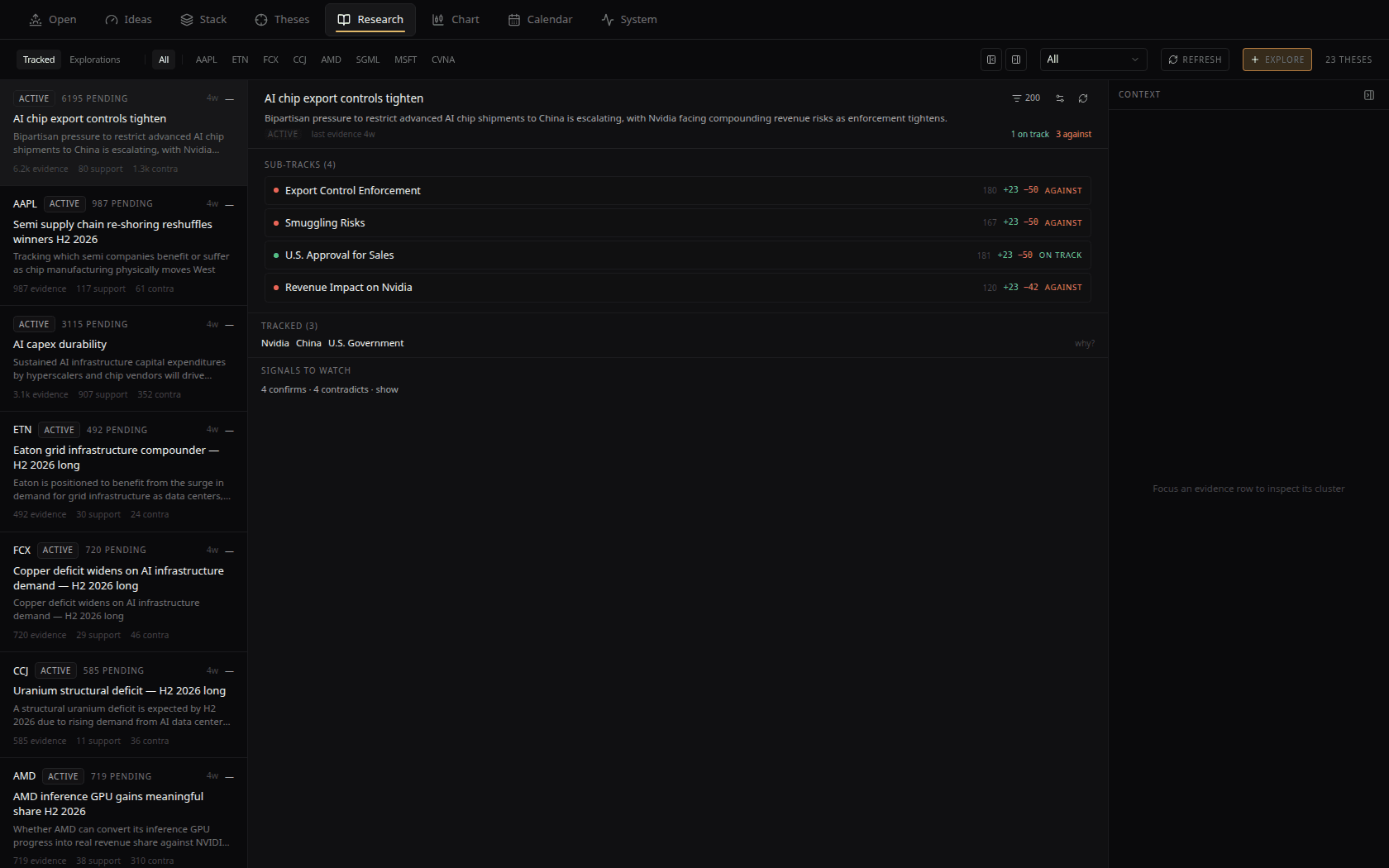
The research workspace
Theses, not chat sessions. A thesis is a persistent hypothesis with matching rules and an accumulating evidence ledger. A matcher scans new articles, filings, and call transcripts every 60 seconds and binds hits with the reason and similarity that produced them. Stance classification runs against the thesis statement: supports, contradicts, neutral, with a one-line rationale. Conviction comes from the ledger, not from asking the model how it feels.
How it’s built
.NET 10 API, React frontend, Postgres 17 with pgvector. Three Python sidecars: embeddings, zero-shot triage, Whisper transcription. Ollama on the host for the constrained-JSON jobs. Everything runs on one machine; no data leaves it.
A Postgres work queue with leases, retries, and dead-lettering drives the drains. A pipeline run ledger records every cycle: inputs, outputs, skips, errors by category. Green sources tell you ingestion ran; a green ledger tells you events actually landed.
The hard parts
- Scoping the LLM. Every step that can be arithmetic is arithmetic; the model is reserved for judgments where it has a real edge, and each one is bounded by a thesis statement and grounded in cluster context. There is no “ask the model about the market” surface. That is the design.
- Source trust. Five reputation tiers from EDGAR down to Reddit, with explicit weights. The math is supposed to drown low-trust breadth under low importance, and the tier system is what makes an aggregator headline lose to a filing.